 One paper has been accepted to ICLR 2025
One paper has been accepted to ICLR 2025
The International Conference on Learning Representations (ICLR) is one of the major conferences in the field of artificial intelligence. (Accept. rate 30.1%)
One paper has been invited to ICLR 2025 as poster presentation
Since 2024, ICLR is inviting ~100 TMLR accepted papers within 2 years (~6.61%) with outstanding reviewer scores or AE recommendations as the ICLR’s poster presentation (Link).
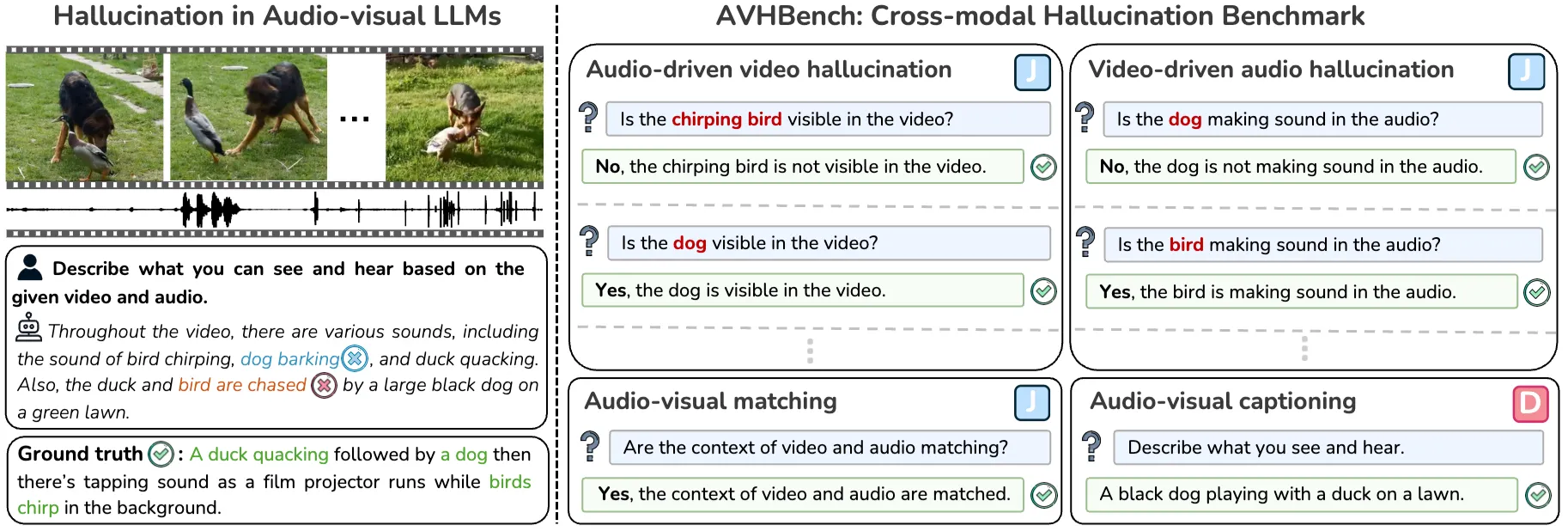
AVHBench: A Cross-Modal Hallucination Benchmark for Audio-Visual Large Language Models
Authors: Kim Sung-Bin* (POSTECH), Oh Hyun-Bin* (POSTECH), JungMok Lee (POSTECH), Arda Senocak (KAIST), Joon Son Chung (KAIST) Tae-Hyun Oh (POSTECH)
Following the success of Large Language Models (LLMs), expanding their boundaries to new modalities represents a significant paradigm shift in multimodal understanding. Human perception is inherently multimodal, relying not only on text but also on auditory and visual cues for a complete understanding of the world. In recognition of this fact, audio-visual LLMs have recently emerged. Despite promising developments, the lack of dedicated benchmarks poses challenges for understanding and evaluating models. In this work, we show that audio-visual LLMs struggle to discern subtle relationships between audio and visual signals, leading to hallucinations, underscoring the need for reliable benchmarks. To address this, we introduce AVHBench, the first comprehensive benchmark specifically designed to evaluate the perception and comprehension capabilities of audio-visual LLMs. Our benchmark includes tests for assessing hallucinations, as well as the cross-modal matching and reasoning abilities of these models. Our results reveal that most existing audio-visual LLMs struggle with hallucinations caused by cross-interactions between modalities, due to their limited capacity to perceive complex multimodal signals and their relationships. Additionally, we demonstrate that simple training with our AVHBench improves robustness of audio-visual LLMs against hallucinations.
A Large-Scale 3D Face Mesh Video Dataset via Neural Re-parameterized Optimization
Authors: Kim Youwang (POSTECH), Lee Hyun* (POSTECH), Kim Sung-Bin* (POSTECH), Suekyeong Nam (KRAFTON), Janghoon Ju (KRAFTON), Tae-Hyun Oh (POSTECH)

Abstract
We propose NeuFace, a 3D face mesh pseudo annotation method on videos via neural re-parameterized optimization. Despite the huge progress in 3D face reconstruction methods, generating reliable 3D face labels for in-the-wild dynamic videos remains challenging. Using NeuFace optimization, we annotate the per-view/-frame accurate and consistent face meshes on large-scale face videos, called the NeuFace-dataset.
We investigate how neural re-parameterization helps to reconstruct image-aligned facial details on 3D meshes via gradient analysis. By exploiting the naturalness and diversity of 3D faces in our dataset, we demonstrate the usefulness of our dataset for 3D face-related tasks: improving the reconstruction accuracy of an existing 3D face reconstruction model and learning 3D facial motion prior.